Table of Contents
Introduction
In this course, we build on our knowledge of NumPy by looking in detail at the data structures provided by the Pandas library. Pandas is a newer package built on top of NumPy, and provides an efficient implementation of a DataFrame.
DataFrames are essentially multidimensional arrays with attached row and column labels, and often with heterogeneous types and/or missing data. As well as offering a convenient storage interface for labeled data, Pandas implements a number of powerful data operations familiar to users of both database frameworks and spreadsheet programs.
At the very basic level, Pandas objects can be thought of as enhanced versions of NumPy structured arrays in which the rows and columns are identified with labels rather than simple integer indices.
The Series and DataFrame Objects
One of the keys to understanding pandas is to understand the data model. At the core of pandas are two data structures. The most widely used data structures are the Series and the DataFrame for dealing with array data and tabular data, respectively.
Using the EXCEL analogy, a DataFrame is similar to a spreadsheet with rows and columns, while a Series is similar to a single column of data.
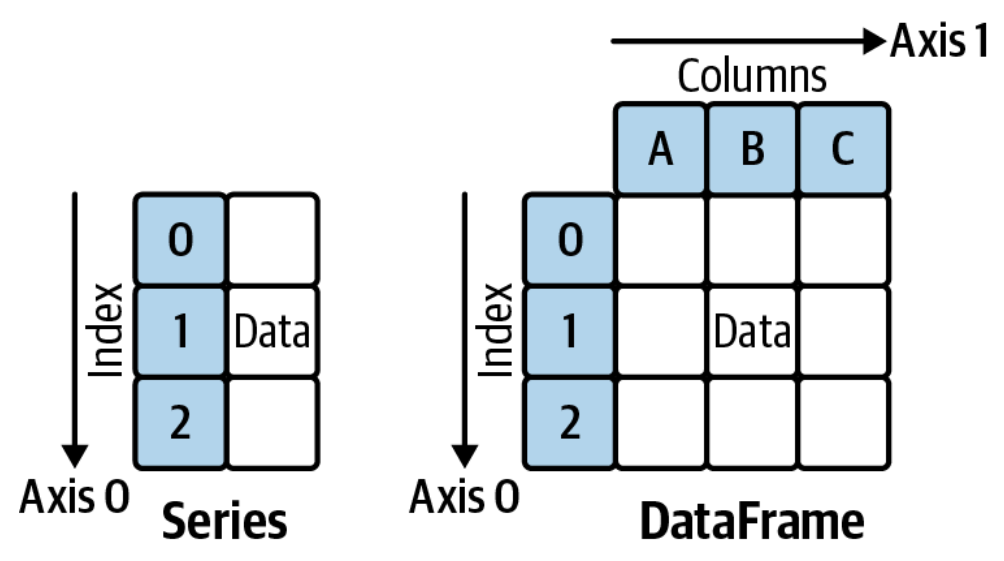
In pandas, axis = 0 refers to horizontal axis or rows and axis = 1 refers to vertical axis or columns. In this course, we will focus on the mechanics of using Series, DataFrame, and related structures for effective data wrangling.